Descriptive Statistics in Six Sigma plays an important role. But, if we do not display that data in a way that can be easily understood, then it becomes useless to us or, worst yet, we might draw the wrong conclusions from it.
In this module, we discuss Descriptive Statistics as used in the Measure Phase of Six Sigma. We’ll go through the key measures that describe key characteristics of variation in a data set.
Descriptive Statistics includes measures of location and measures of dispersion.
Measures of Location
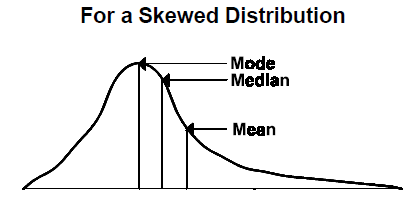
Measures of Location is formally called measures of central tendency. For this type of descriptive statistic, we are mostly interested in the Mean, Median, and the Mode.
Mean
In a data set, measures of central tendency is a way to represent the central value in a collection of data. The basic name for this value is The Mean, often times called X-Bar.
The Mean is the sum total of all the data values divided by the number of data points. You know this value by its common name – the average.
Median
The Median is the midpoint or the middle value when the data is arranged from smallest to largest. For an even set of data, the Median is the average of the middle two values.
For example, take the data set below:
3, 5, 7, 12, 13, 14, 21, 23, 23, 23, 23, 29, 40, 56
Because this data set is even, the middle two numbers can be added and then divided by two to arrive at the average, which will be our median:
21 + 23 = 44
44 / 2 = 22 is the Median.
Mode
The Mode is the most frequently occurring number in a data set. For example, consider the data set below:
3, 5, 7, 12, 13, 14, 20, 23, 23, 23, 23, 29, 39, 40, 56
In this data set that is sorted from smallest to largest, 23 occurs four times, which is the most frequent occurring number and, hence, 23 is the mode in this data set.
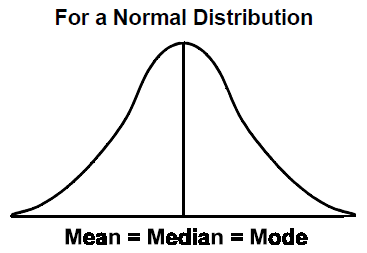
If the data set is normally distributed, then the Mean = Median = Mode like the following:
Measures of Dispersion
For smaller data sets, the Range and Interquartile Range are good measures that indicate variability in the data set.
To see the spread of a data set, we are mostly interested in the dispersion of the data. For this, we are curious about the Range, Interquartile Range, Standard Deviation, and the Variance.
Range
The range in descriptive statistics is the difference between the largest observation and the smallest observation in the data set.
Range = Max – Min
A small range would indicate a small amount of variability. A large range would indicate a large amount of variability.
Interquartile Range
The Interquartile Range is the difference between the 75th percentile and the 25th percentile.
IQR = Q3 – Q1
When your data looks skewed, the Range and IQR are good quick indicators that tell you something about the variability in the data set.
As the data set gets larger, however, the standard deviation becomes a more reliable measure of variability.
Standard Deviation
The Standard Deviation, or Sigma, is the average deviation of values from the mean of a given data set. Simply, it’s the average spread from the mean.
Variance
The variance is the average squared deviation of each individual data point from the mean.
Let’s Do An Example
Let’s go through an example that demonstrates the Mean, Variance, and Standard Deviation.
Suppose you measured several dogs at the park. Below are the heights of the dogs in millimeters:
- 600
- 470
- 170
- 430
- 300
To get the Mean,
600+470+170+430+300 = 1970
Mean = 1970 /5 = 394
Now, let’s calculate the Variance. First, we need to calculate the difference or each dog’s height from the Mean.
- 600-394 = 206
- 470-394 = 76
- 170-394 = -224
- 430-394 =36
- 300-394 = -94
Now, we square each of the sums above like so:
Variance = [206^2 + 76^2 + (-224)^2 + 36^2 +(-94)^2] / 5 = 21704
To get the Standard Deviation, we only need to square root the variance:
SQRT(21704) = 147
Up Next
Next, we’ll discuss the various distributions commonly used by Six Sigma Black Belts in DMAIC Projects.
| Blog Article | Excel | PowerPoint | Video |
| Module | Description | Type | |
| Overview |
What is Six SigmaThe various definitions of Six Sigma is explained in this 5:42 video. We specifically discuss 6 definitions of "Sigma", ending with the most relevant definition which is related to the DMAIC Method of Problem Solving. |
||
| Overview |
The DMAIC FrameworkIn this 4:17 video, we explain the DMAIC framework and give an introduction to each phase in DMAIC. We specifically show the storyboard for each phase in the DMAIC framework. |
||
| Overview |
DMAIC versus PDCAArticle describes how PDCA is used in Lean and the similarities and common history between PDCA and DMAIC. |
||
| Overview |
History of Six Sigma and LeanIn this video, we go through the various contributors of Six Sigma, their contribution, and why it's important in the practice of modern Six Sigma. We also go into the history of the Toyota Production System and how the term "lean" was coined. Video is 7:36 long. |
 |
|
| Overview |
Lean History and TimelineThis article shows a comprehensive history and timeline of Lean and of continuous improvement beginning in the 1600's. |
||
| Overview |
Black Belt CertificationIn this article, we provide various resources where you may take the Black Belt exam should you choose to do so. We also discuss the positive and negative of Black Belt certification. |
||
| DEFINE | |||
| Define |
The Define Phase StoryboardWe introduce the Define Phase and show the Define Storyboard, a high level map of what the phase is about and the expected outputs. Video length is 3:50. |
||
| Define |
Business Needs AssessmentIn this video, we discuss how to identify business needs of an organization and how to take that knowledge and transform it into a formal DMAIC project that will get the backing and support from top management. Video length is 6:46. |
||
| Define |
Project CharterIn this 5:37 minute video, we explain the role of the project charter and its importance in Six Sigma DMAIC projects. Video length is 5:37. |
||
| Define |
Project Selection MatrixIn this short 2:51 minute video, we learn a simple and effective method for prioritizing between competing priorities. This method is important for the selection of an improvement project. |
||
| Define |
Problem StatementArticulating the problem well gets you much closer to a solution. In this video, we show you how along with several real world examples of effective problem statements. Video length is 5:42. |
||
| Define |
Stakeholder AnalysisIdentifying stakeholders and their needs is one of the most important steps in Define. This is especially crucial if there are any influential stakeholders that are resistant to your message. Video length is 2:47. |
||
| Define |
Affinity DiagramAffinity Diagram is a tried and true method for brainstorming and coming up with ideas. Learn how to apply this technique in this video. Video length is 4:25. |
||
| Define |
SIPOCIdentifying the key spots where measurements can be taken in crucial. This video will show you how to do it. Video length is 3:01. |
||
| Define |
Voice of the Customer and CTQIn this video spanning 5:11, we explain Voice of the Customer and how Six Sigma is rooted in the customer. We explain how to translate Voice of the Customer into Critical to Quality Metrics. |
||
| Define |
Critical to Quality TreeArticle explaining the critical to quality tree, with examples, and a template to download so you can create your own for your six sigma projects. |
||
| Define |
Value Stream MapIn this 4:42 video, you will learn understand the value stream map symbols and learn how to design your own value stream map. We provide a zip file of VSM Symbols for you to download. |
||
| Define |
Kano ModelWe explain the Kano Model to identify service and product characteristics that should be "satisfiers" and the ones that be "good enough" and don't need to go any further. |
||
| MEASURE | |||
| Measure |
The Measure Phase StoryboardWe introduce the Measure Phase and show the Measure Storyboard, a high level map of what the phase is about and the expected outputs. |
||
| Measure |
Data Types in Six SigmaIn this article we explain the various types of data, how they're different, and what they tell us about process behavior. We will also learn how to collect data. Video length is 5:24. |
||
| Measure |
Descriptive StatisticsIn this module we learn various data measures that tell us key characteristics of a data set. We also begin the foundation for our discussion on distributions in a later module. |
||
| Measure |
DistributionsThis is a brief introduction to statistical distributions and what inferences we can draw from them. |
||
| Measure |
Graphical Representation of DataGraphically representing data effectively is required to effectively communicate meaning. In this module we learn various graphical methods and how to do them. |
||
| Measure |
7 Quality ToolsWe briefly introduce each of the 7 quality tools. We follow this video several videos where we focus on the detailed of each of the 7 quality tools. Video length is 4:46. |
||
| Measure |
Check SheetsIn this HD video, we explain the checksheet, what it is used for, see various examples of checksheets, how to create one, and be able to download a checksheet template from the Shmula content library. Video length is 3:53. |
||
| Measure |
Pareto ChartIn this 4:48 minute video, you will learn the history of the Pareto Principle, why it's important, and how to apply the Pareto Principle in your lean and six sigma efforts using excel. |
||
| Measure |
HistogramThis video on the Histogram explains what it is, when to use it, and how to use it. Video length is 3:01. |
||
| Measure |
Scatter PlotIn this 4:27 short video, we introduce the Scatterplot, what it is, why use it, and how it can be helpful in your six sigma projects. |
||
| Measure |
Cause and Effect DiagramThis 5:21 minute video explains the cause and effect diagram - what it is, when to use it, and how to create one. |
||
| Measure |
Control ChartIn this video, we introduce you to the control chart - what it is, where to use it, when to use it, and how it's used. Video length is 7:05. |
||
| Measure |
Run ChartIn Progress |
In Progress | |
| Measure |
Process Cycle EfficiencyProcess Cycle Efficiency is a more modern tool that looks at processes from the perspective of value and waste. We show you how to do it and why it's important. |
In Progress | |
| Measure |
FMEAFailure Mode Effects Analysis is a tried and true method and technique for quickly identifying ways where process problems can occur and how to quickly mitigate them. Video length is 4:45. |
||
| Measure |
Basic StatisticsIn this article, we go in depth to explain basic data types, scales, and the language of six sigma. |
||
| Measure |
Using Z ValuesWe learn about Z Values or the Z Score with applications in Six Sigma projects. |
||
| Measure |
Sample Size CalculationsIn this module we learn the underpinnings of sample size calculations and how they are used in six sigma. We provide a sample size calculator in the template section also. |
||
| Measure |
Introduction to VariationThis article introduces the learner to the concept of variation and how it impacts the customer experience. |
||
| Measure |
Red Bead Experiment Part 1Introduction to red bead experiment. |
 |
|
| Measure |
Red Bead Experiment Part 2In part 2, we actually do a quick run through the experiment. |
 |
|
| Measure |
Red Bead Experiment Part 3In this video, we explain and go through more runs of the experiment. |
 |
|
| Measure |
Red Bead Experiment Part 4In this video we continue our experiment and go through some of Dr. Deming's most famous quotes. |
 |
|
| Measure |
Red Bead Experiment Part 5Continuing the experiment, with a focus on how to best facilitate an event. |
 |
|
| Measure |
Red Bead Experiment Part 6In this last video in the series, we go through the key lessons learned from Deming's famous experiment on variation. |
 |
|
| Measure |
Measurement System AnalysisIn this video we discuss variation and how it impacts our methods of measuring. Video length is 5:28 and we show examples along with tips on how to deal with bad metrology. Video length is 5:28. |
||
| Measure |
Gauge R&RIn this video we explain the Gauge R&R Test and provide various examples of where and how it may be applied in industry. |
In Progress | |
| ANALYZE | |||
| Analyze |
The Analyze Phase StoryboardWe introduce the Analyze Phase and show the Analyze Storyboard, a high level map of what the phase is about and the expected outputs. |
In Progress | |
| Analyze |
BrainstormingWe introduce various methods of brainstorming. Some conventional and some not very and more modern. Some of these methods are taken from Design Thinking and have been found to be very effective in identifying innovative and simple solutions to problems. |
In Progress | |
| Analyze |
5 Whys and Fishbone DiagramIn this video we explain the 5 Why exercise and show many examples. We extend the 5 Whys and show how it naturally leads to the Fishbone Diagram. |
In Progress | |
| Analyze |
Verifying Root CausesWe introduce hypothesis testing and various methods for doing so including the Regression, T Test, Chi Square, and ANOVA. |
In Progress | |
| Analyze |
Hypothesis TestingIn Progress |
In Progress | |
| Analyze |
RegressionIn Progress |
In Progress | |
| Analyze |
T TestIn Progress |
In Progress | |
| Analyze |
Chi SquareIn Progress |
In Progress | |
| Analyze |
ANOVAIn Progress |
In Progress | |
| IMPROVE | |||
| Improve |
The Improve Phase StoryboardWe introduce the Improve Phase and show the Improve Storyboard, a high level map of what the phase is about and the expected outputs. |
In Progress | |
| Improve |
Change ManagementWe introduce you to several change management models that have been found to effective in practice. We show what they are, how to do them. |
In Progress | |
| Improve |
Solution Selection MatrixThe Solution Selection Matrix is a simple tool that helps a team vote and decide on which solution makes the most sense to put resources behind in improvement projects. |
In Progress | |
| Improve |
Process CapabilityWe discuss process capability and how it's different from a process not in control. We discuss its importance. |
In Progress | |
| Improve |
Cost / Benefit AnalysisWe introduce the concept of Cost and Benefit Analysis and provide several ways at showing cost savings from Six Sigma Projects. |
In Progress | |
| Improve |
Poka YokeAs part of the Improve Phase, we introduce the concept of Poka Yoke, or error proofing, as a way to prevent defects before they even occur. We show may examples and teach the principles behind Poka Yoke. |
In Progress | |
| CONTROL | |||
| Control |
The Control Phase StoryboardWe introduce the Control Phase and show the Control Storyboard, a high level map of what the phase is about and the expected outputs. |
N/AN/A | |
| Control |
Before / After ParetoWe show ways to visually see before and after results of your project. |
In Progress | |
| Control |
Standard Pig GameIn this 4:55 minute video, we show you a simple and effective game that teaches the importance of Standard Work. This video should be watched prior to the video on Standard Work. |
||
| Control |
Standard WorkStandard Work is a foundation of Lean and Six Sigma. In this 5:36 minute video we explain Standard Work and show its role in continuous improvement. |
||
| Control |
Control ChartsWe discuss the various control charts, why they're important, and how to create them given your process and given your data type. |
In Progress | |
Become a Lean Six Sigma professional today!
Start your learning journey with Lean Six Sigma White Belt at NO COST




